What is Axon?
Building an agent today means making the same decisions every time. How do you assemble context? When does the loop stop? What happens when a tool call fails? How do you persist sessions across requests? Every team answers these questions from scratch, builds something that mostly works, and maintains it forever.
Axon answers them once. The result runs under every agent you build — so the only thing you're actually building is the agent.
The runtime is already built
You define what the agent knows, what it can do, and what it's allowed to do. Everything else — assembling the context window, dispatching tool calls, running the loop, persisting sessions, enforcing policy — is handled. The boundary is a single call:
const { stream } = axon.stream({ prompt: [session, task], thread: "project-alpha" })
No loop to implement. No retry logic. No session management. You stream entries and process them. The infrastructure that every agent needs — maintained once, available to all of them.
Capabilities are installed, not implemented
The integrations you'd otherwise spend a week on — GitHub, Linear, Discord, Stripe — are modules. Install one and it wires itself in: webhook verification, event normalization, typed tools, boot-time client setup. All of it.
axon install @axon/github
axon install @axon/linear
Your agent gains github.openPr, github.getPrDiff, linear.createIssue as typed,
documented tool calls the model can invoke. You didn't write the integration. You just
have it.
Modules compound. The registry grows, and every new capability is one install away for every agent you've ever built. Browse what's available at axon.arclabs.it/docs/agents.
The terminal interface
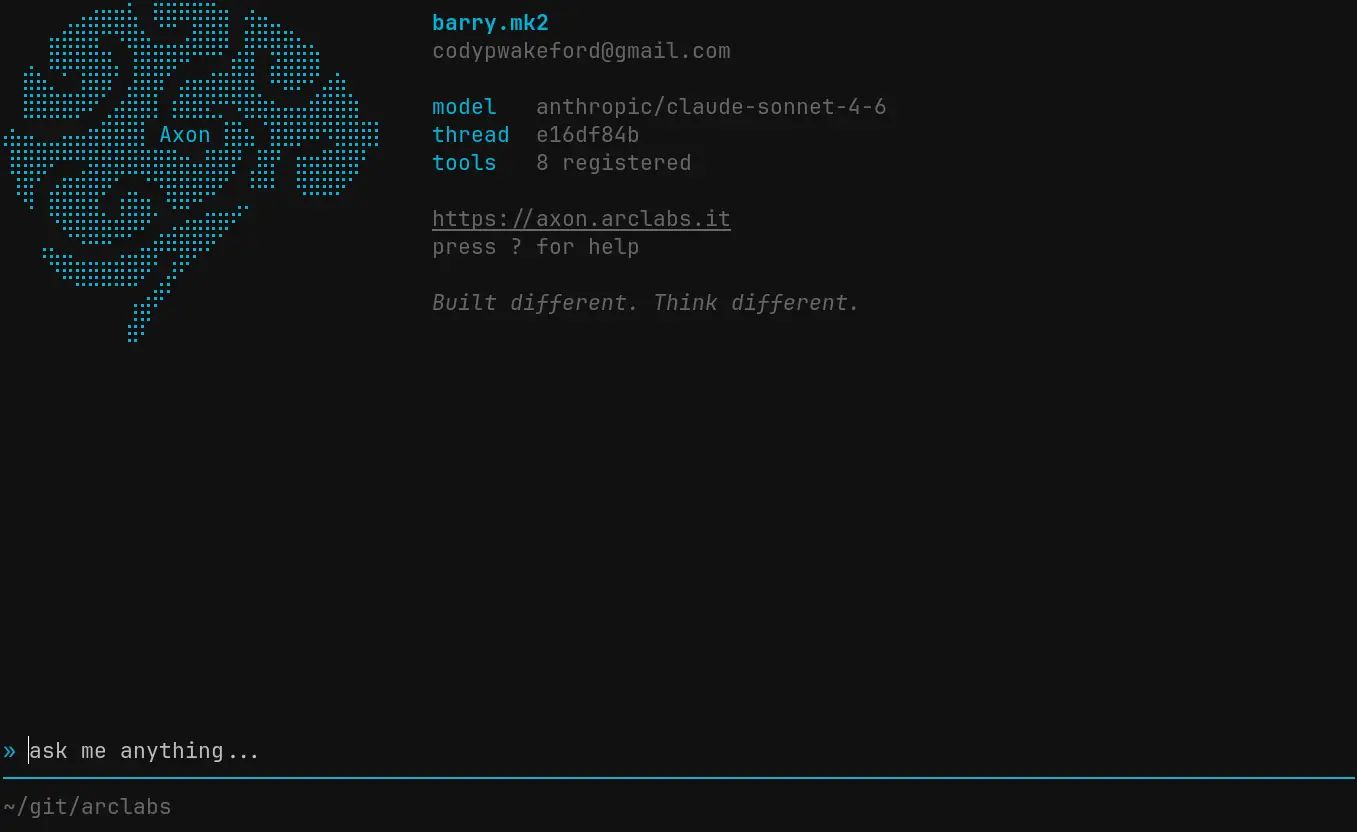
This is where you work with agents. Every tool call visible. Every session navigable. Scripts invoked with a keypress. The interface was designed for agents specifically — not adapted from something else.
The mode system puts everything within one or two keystrokes. ! to run a script. @ to
browse sessions. * to switch models. > to load a prompt into the input. It runs on a
custom renderer operating well below a millisecond per frame.
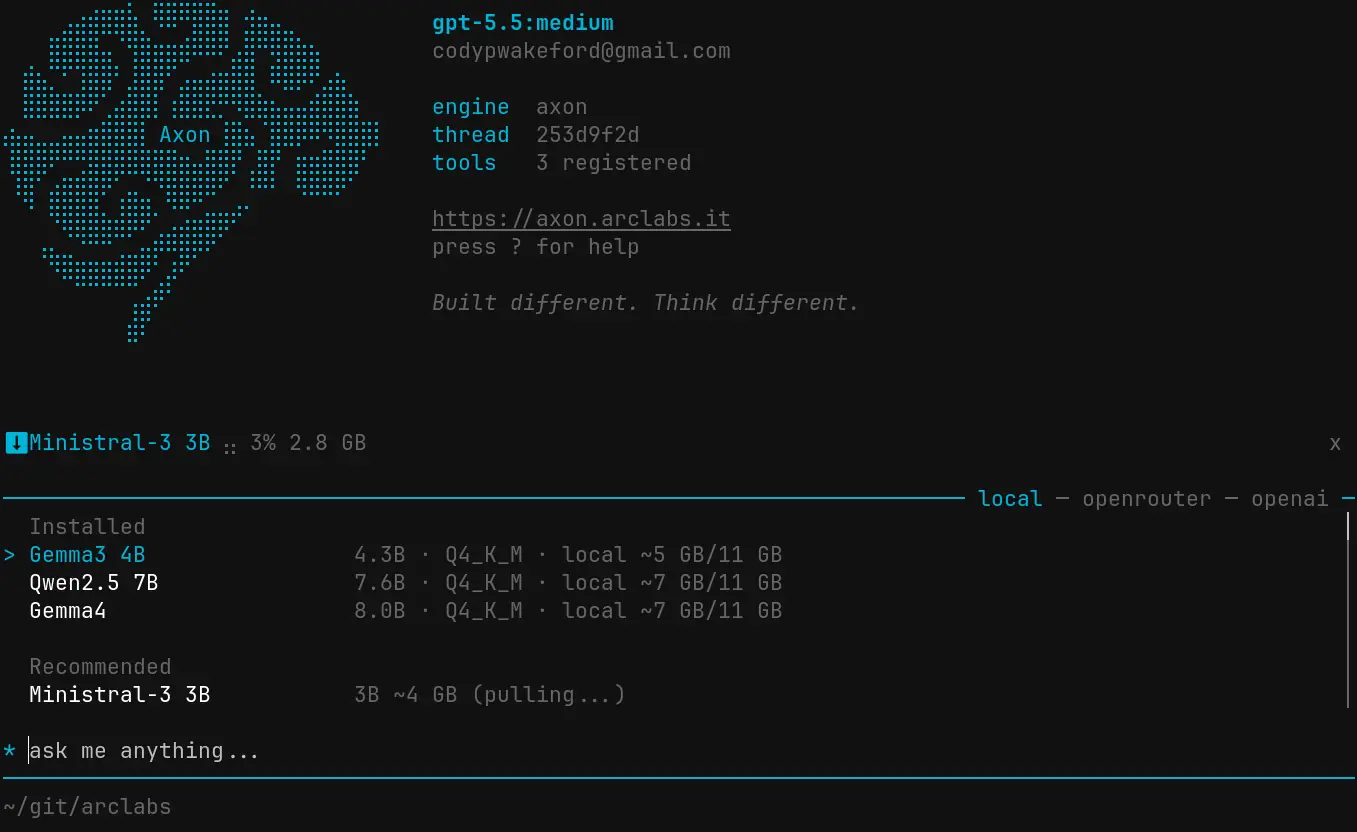
It also manages Ollama. Browse the local model library filtered to your hardware, select one, and it starts downloading. Switch between cloud and local inference from the same palette without changing anything about how your agent works.
One command to ship it
axon deploy
Your agent gets a public URL, an API key, and durable cloud storage. No Dockerfile, no
infra to configure, no runtime to manage. Prefer to run it yourself? axon build
produces a Docker image ready for any container platform. The folder is the same either
way.
Ready to build. Agent is where the full story lives.
Already using an agent and want to go deeper. TUI covers the interface in full.